Introduction
Why did I decide to write an article today about Git and Mercurial?
Just because a customer I work for (a big space company) has decided to migrate from Clearcase to Git for new projects. So I was very interested in Git and my feeling for GIT is very ambivalent: This tool is both awesome and awful!
From this in-depth study of Git is born a certain "frustration" to see a blind craze for the Git tool while this tool can, potentially, have disastrous consequences if it is misused. What's more, it lacks something fundamental: the branches! ... I mean the real branches! Not what Git calls branches ... the real ones, as they are defined in Mercurial, Clearcase, SVN or CVS! But I will come back to it very quickly because this misnomer gives a false idea about the possibilities of Git.
So I looked at other tools, including Mercurial. To be perfectly honest, I was not so far in my study of Mercurial but I made very quickly 5 observations:
- The branches of Mercurial are real branches
- The representation of the history is much clearer (related to the previous point)
- it is more rigid than Git but I am not sure that we can not rig or destroy the history
- Its commands are more simple and more logical.
- It's as easy to install as Git
Coming from an industrial space world where rigor and traceability are fundamental, former Clearcase administrator, I consider that the quality of the version management tool (or also configuration management) is fundamental.
Git may be a good choice, but it must be done knowingly and not blindly "because it's fashionable!" It all depends on what you expect from the tool.
- With GIT, we can do everything: Super, good reason to use it!
- With GIT, you can do everything, including completely falsifying a history or destroying it: Aie! We should avoid it!
Indeed, Git was written by computer scientists, tenors of the scripting and the command line, for computer scientists,! Respects! But here, where it starts to be embarrassing, is that to use it well, you have to understand how it works, how it manages its data, what are the implications of the commands that you will execute ... What is acceptable for a team of savvy developers working daily with Git is however much less for companies for whichit is not the core business but still develop software and needs traceability.
In industry, what is the expectation of such a tool?
- That it is not too heavy: OK, Git is very simple to install and make a repo git for a project is very very simple! "Git init" at the top of the project and the that's it (or almost). Same thing for Mercurial
- That he saves the different versions of the project: OK, Git does the job, Mercurial too.
- That it gives a clear view of the history of the project: Aie! Git will give a good view, but to say that it is clear ... no, if you have worked with other configuration management tools, you will agree with me: The representation of Git is anything but clear! The fault to what ... Again, how Git manages the banches! In the article "How to manage client branches with Git and Mercurial", I had to put some representations to clarify the situations .. Thanks to Mercurial and EasyMercurial who allowed me to make these representations easily! Okay, it would be enough to make an "EasyGit" to make clear representations ... Well... no! because Git does not keep the necessary info! (yes, still the branches! ;-)). Mercurial does it better.
- The tool must be reliable and guarantee that there will be no loss of data: Well... Actually, with a server repo and handling the permissions correctly, there is a way to secure it ... but it's not like that "out of the box" and you will have to learn how to do it on a remote server.
- The learning time must be relatively short. Ouch! See above, to use it properly, you have to understand how it works ... and it takes time! In a company, trainings are expensive and it will often be more advisable to devote this budget to training related to the business rather than training on peripheral tools.
Git is really very flexible and suitable for scripting. It obviously pleases all the hackers I'm part of. But would I use it for a team developing a project for which I am responsible ... clearly NO, I am too afraid of not controlling anything after a few weeks. And yet, it would not take much for that bigger default disappears ... but it would require GIT to "change philosophy" about branches(at least accept that branch name could be considered as an important information to keep during the whole repository life) and, after I've tried to convince them (and submit a patch that did the job), I'm not sure it will happen soon.
Git and the "branches"
If you do a google search on "git branching model", here is what you will get:
The good joke! On all these graphs, each branch is a straight line! What make you believe that you will see it one day. And in real life, git will NEVER be able to represent history like that, even with the best tool in the world ... and for good reason, it does not have (not anymore!) the information needed to do so. . Mercurial, on the contrary, is quite capable of doing so. That's where I'm sad, why, while he had all the information, Git only stores it temporarily (in the refslog for the savvy ones). Why not just add the name of the branch in which the commit was made to its "commit object". It would solve "everything", in any case a big part of the problem. In fact, what Git calls a branch, is actually a dynamic tag, ie a tag that, when it is active during a commit, go ahead with it.
Another false good idea in Git (this is just my point of view), these are the "fast-forward". What is this thing ? it is simply the fact that when a merge is "trivial" (the version after the merge is identical to the merged version), the 2 branches (are then confused) .
In fact, here's what it gives:
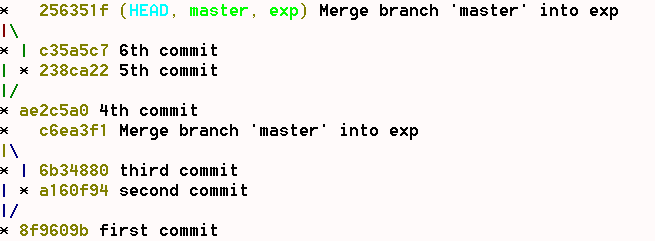
Already with this very simple example, we see that it will be impossible to associate a commit to a branch (the info is only stored locally and temporarily). As a result, all the tools that attempt to represent a history will lack the necessary information to do so.
And if we do not use fast-forward ...

It's already better but our example is very simple, only has 6 commits and 2 branches ... my experience showed me that even without fast forward, it will sometimes be very difficult to understand a history.
And if the name of the branch was in the commit ... would not it already be much clearer?
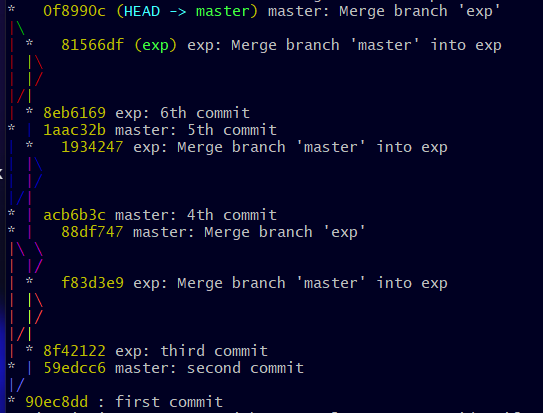
It's already much better and that's what I use professionally, given the migration I mentioned earlier.
And Mercurial, what would he have given?
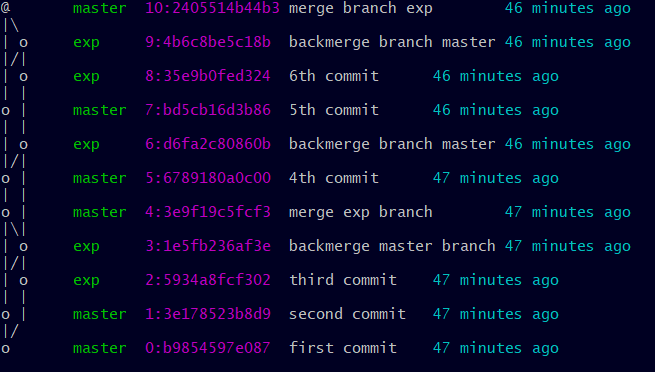
and with EasyMercurial:
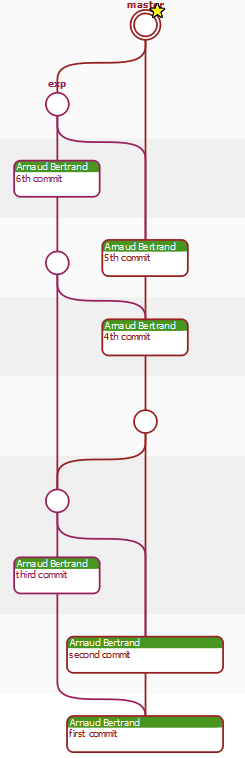
So, is it not clearer ??? You understand my "frustration". If Git kept the name of the branch in each commit, it could probably do as well as Mercurial, but today that is unfortunately not the case.
Some months after this, I've started a project ggrap(for git graph) that try to analyze the git repository and try to determine the branch. It can be helped by tagging some commits or by using hooks that add branchname in head of commit comments.
It is still experimental and for the moment, does not manage multiple repositories sources, so, there is sometime a wrong information but in most of the case, it is really better then what git shows nativey.
The project link is on ... github! ... here https://github.com/abalgo/ggraph
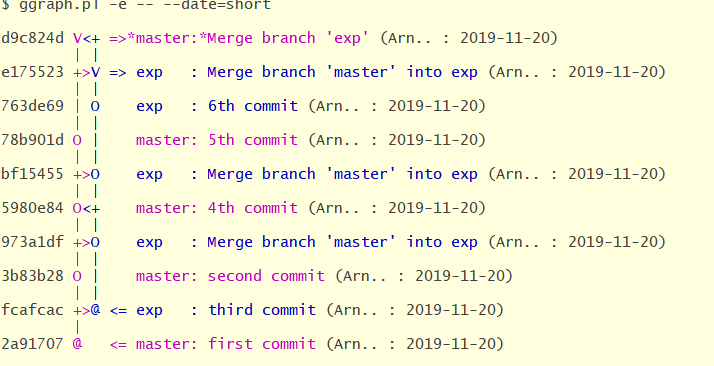
With this, we are near to Mercurial but it is not native and request some settings or some tags by users which reduce the reliability of the information.
A. Bertrand 21/05/2020
- Log in to post comments