Introduction
Pourquoi ai-je décidé d'écrire aujourd'hui un article sur Git et Mercurial ?
Simplement parce qu'un client pour lequel je travaille (une grosse société active dans le domaine spatial) a décidé de migrer de Clearcase vers Git pour ses nouveaux projets. Je me suis donc intéressé de près à Git et mon sentiment à l'égard de GIT est très ambivalent: Cet outil est à la fois génial et à la fois horrible!
De cette étude approfondie de Git est néé à une certaine "frustration" de voir un engouement aveugle pour l'outil Git alors que cet outil peut, potentiellement, avoir des conséquences désastreuses s'il est mal utilisé. Qui plus est il lui manque quelque chose de fondamental: les branches! ... Je veux dire les vraies branches! Pas ce que Git appelle des branches... les vraies, telles qu'elles sont définies dans Mercurial, Clearcase, SVN ou CVS ! Mais j'y reviendrai très vite car cet abus de langage donne une idée fausse sur les possibilités de Git.
J'ai donc regardé d'autres outils, dont Mercurial. Pour être tout à fait honnête, je n'ai pas été aussi loin dans mon étude de Mercurial mais j'ai fait très rapidement 5 constats:
- Les branches de Mercurial sont de vraies branches
- La représentation de l'historique est beaucoup plus claire (lié au point précédent)
- il est plus rigide que Git mais je ne suis pas certain qu'on ne puisse pas truquer ou détruire l'historique
- Ses commandes sont plus simples et plus logiques.
- Il est aussi simple à installer que Git
Venant d'un monde industriel spatial ou la rigueur et la traçabilité sont fondamentales, ancien administrateur Clearcase, je considère que la qualité de l'outil de gestion de versions (ou aussi gestion de configurations) est fondamentale.
Git peut être un bon choix mais il doit être fait en connaissance de cause et pas aveuglément "parce que c'est la mode!". Tout dépend de ce qu'on attend de l'outil.
- Avec GIT, on peut tout faire : Super, bonne raison pour l'utiliser!
- Avec GIT, on peut tout faire, y compris fausser complètement un historique ou le détruire : Aie! Nous devrions l'éviter!
En effet, Git a été écrit par des informaticiens, des ténors du scripting et de la ligne de commande, pour des informaticiens, ! Respects! Mais voilà, là ou ça commence à être gênant, c'est que pour bien l'utiliser, vous devez comprendre comment il fonctionne, comment il gère ses données, quels sont les implications des commandes que vous allez exécuter... Ce qui peut paraître acceptable pour équipe de développeurs avertis et travaillant au quotidien avec Git l'est par contre beaucoup moins pour des sociétés dont ce n'est pas le métier de base mais qui développent quand-même du software et a besoin de traçabilité.
En industrie, qu'attend-t-on d'un tel outil ?
- Qu'il ne soit pas trop lourd: OK, Git est très simple à installer et faire un repo git pour un projet est très très simple!"git init" au top du projet et le tour est joué (ou presque). Même constat pour Mercurial
- Qu'il enregistre les différentes versions du projet: OK, Git fait le job, Mercurial aussi.
- Qu'il donne une vue claire de l'historique du projet: Aie! Git donnera bien une vue, mais de là à dire qu'elle est claire... non, si vous avez travaillé avec d'autres outils de gestion de configurations, vous serez d'accord avec moi: La représentation de Git est tout sauf claire! La faute à quoi... A nouveau, à la façon de gérer les banches! Dans l'article "Comment gérer es branches clients avec Git et Mercurial", j'ai du mettre des représentations afin de clarifier les situations.. Merci à Mercurial et à EasyMercurial qui m'ont permis de faire ces représentations de manière aisée! Ben du coup, il suffirait de faire un "EasyGit" pour faire des représentations claires... Eh ben non! parce que Git ne garde pas les infos nécessaires ! (oui, encore les branches! ;-) ). Mercurial le fait mieux.
- L'outil doit être fiable et garantir qu'il n'y aura pas de perte de donnée: BOF. En fait, avec un repo maître et en gérant les permissions correctement, il y a moyen de le sécuriser... mais ça n'est pas comme ça "out of the box" et vous devrez apprendre comment faire sur un serveur distant.
- Le temps d'apprentissage doit être relativement court. Aie! Voir plus haut, pour bien l'utiliser, il faut comprendre son fonctionnement interne... et ça demande du temps! Dans une entreprise, les formations coûtent cher et il sera souvent plus judicieux de consacrer ce budget à des formations en lien avec le corps business plutôt qu'à des formations sur des outils périphériques.
Git est vraiment très souple et adapté au scripting. Il plait donc évidemment à tous les bidouilleurs dont je fais partie. Mais est-ce que je l'utiliserais pour une équipe développant un projet dont je suis responsable... clairement NON, j'ai bien trop peur de ne plus rien contrôler au bout de quelques semaines. Et pourtant, il ne faudrait pas grand chose pour que son plus gros défaut disparaisse... mais ça obligerait GIT a "changer de philosophie" sur les branches (tout du moins à accepter que le nom des branches puisse être considéré comme une information importante et conservée sur la durée de vie d'un repository) et après avoir essayer de les convaincre (et proposé un patch qui faisait le travail), je ne suis malheureusement pas certain que ça arrivera de si tôt.
Git et les "branches"
Si vous faites une recherche google sur "git branching model", voici ce que vous allez obtenir:
La bonne blague! Sur tous ces graphes, chaque branche est une ligne droite! De quoi vous faire croire que vous verrez ça un jour. Et dans la vraie vie, git ne sera JAMAIS capable de représenter l'historique comme ça, même avec le meilleur outil du monde... et pour cause, il n'a pas (plus en fait!) les informations nécessaires pour le faire. Mercurial au contraire en est tout à fait capable. C'est là que je suis triste, pourquoi, alors qu'il a toute l'information, Git ne la sauve que de manière temporaire (dans le refslog pour les avertis). Pourquoi ne pas simplement intégrer à son "objet commit" le nom de la branche dans laquelle le commit a été réalisé. Ca solutionnerait "tout", en tout cas une grosse partie du problème. En réalité, ce que Git appelle une branche, n'est en fait qu'un tag dynamique, c'est à dire un tag qui, lorsqu'il est actif lors d'un commit, avance avec celui-ci.
Une autre fausse bonne idée dans Git (ce n'est que mon point de vue), ce sont les "fast-forward". Qu'est-ce que c'est que cette chose, c'est simplement le fait que lorsqu'un merge est "trivial" (la version après le merge est identique à la version mergée), les 2 branches (sont alors confondues).
Dans les faits, voici ce que ça donne:
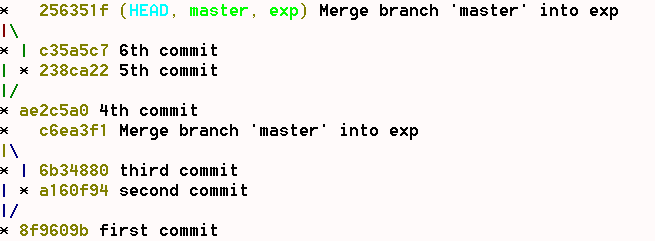
Déjà avec cet exemple très simple, on voit qu'il sera impossible d'associer un commit à une branche (l'info n'est conservée que localement et temporairement). De ce fait, tous les outils essayant de représenter un historique seront dépourvus des informations nécessaires pour le faire.
Et si nous n'utilisons pas les "fast-forward"...

C'est déjà mieux mais notre exemple est très simple, n'a que 6 commits et 2 branches... mon expérience m'a montré que même sans fast forward, il sera parfois très difficile de comprendre un historique.
Et si le nom de la branche était dans le commit... ne serait-ce pas déjà beaucoup plus clair ?
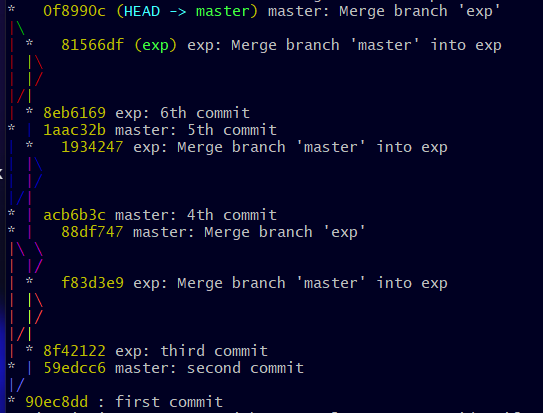
C'est déjà beaucoup mieux et c'est d'ailleurs ce que j'utilise professionnellement, vu la migration dont je vous ai parlé plus haut.
Et Mercurial dans tout ça, qu'aurait-il donné ?
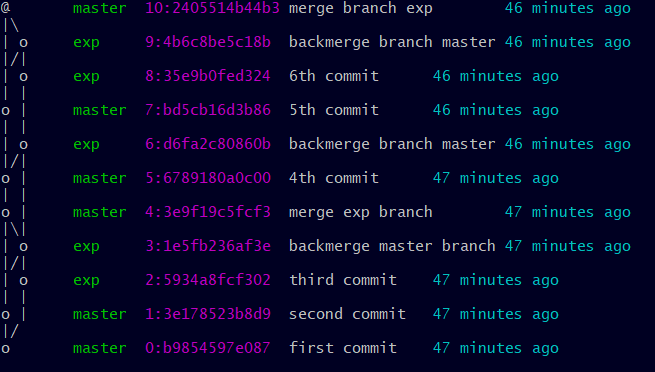
ou avec EasyMercurial:
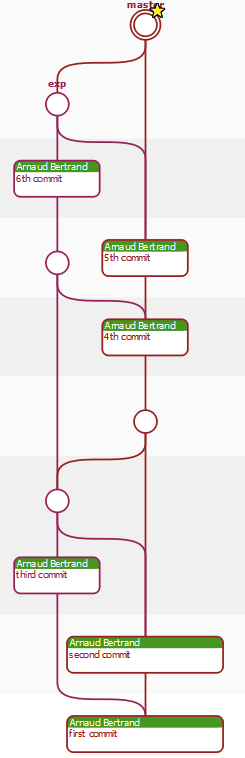
Alors, ce n'est pas plus clair ??? Vous comprenez ma "frustration". Si Git conservait le nom de la branche lors de chaque commit, il pourrait sans doute faire aussi bien, mais aujourd'hui, ce n'est malheureusement pas le cas.
Quelques mois après cela, j'ai démarré un projet ggraph (pour git graph) qui essaie d'analyser le dépôt git et de déterminer les branches. Cela peut être aidé en ajoutant un tag spécifique sur certains commits ou en utilisant des hooks qui ajoutent le nom de la branche dans les commentaires de commit.
C'est encore expérimental et pour le moment, ne gère pas plusieurs sources de dépôt, donc, il y a parfois des informations erronées mais dans la plupart des cas, c'est vraiment mieux que ce que git montre nativement.
Le lien du projet est sur ... github: https://github.com/abalgo/ggraph
Voici un exemple de sortie de la commande
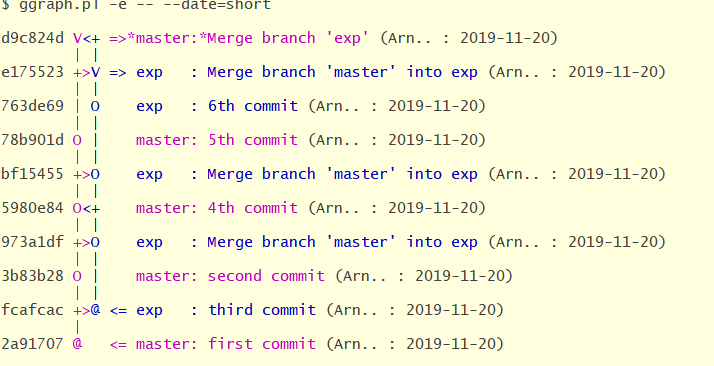
Avec cela, nous sommes proches de Mercurial mais ce n'est pas natif et demande des actions aux utilisateurs (configuration ou tag), ce qui réduit la fiabilité des informations.
A. Bertrand 21/05/2020
- Login om te reageren